CUHK-X
A Large-Scale Multimodal Dataset and Benchmark for Human Action Recognition, Understanding and Reasoning
Due to preparing a competition, we release an example data in this version. Will release all data soon!
Due to preparing a competition, we release an example data in this version. Will release all data soon!
CUHK-X is a comprehensive multimodal dataset containing 58,445 samples across seven modalities designed for human activity recognition, understanding, and reasoning. Unlike existing datasets that focus primarily on recognition tasks, CUHK-X addresses critical gaps by providing the first multimodal dataset specifically designed for Human Action Understanding (HAU) and Human Action Reasoning (HARn).
The dataset was collected from 30 participants across diverse environments using a prompt-based scene creation approach that leverages Large Language Models (LLMs) to generate logical and spatio-temporal activity descriptions. This ensures both consistency and ecological validity in the collected data.
CUHK-X provides three comprehensive benchmarks: HAR (Human Action Recognition), HAU (Human Action Understanding), and HARn (Human Action Reasoning), encompassing eight distinct evaluation tasks. Our extensive experiments demonstrate significant challenges in cross-subject and cross-domain scenarios, highlighting the dataset's value for advancing robust multimodal human activity analysis.
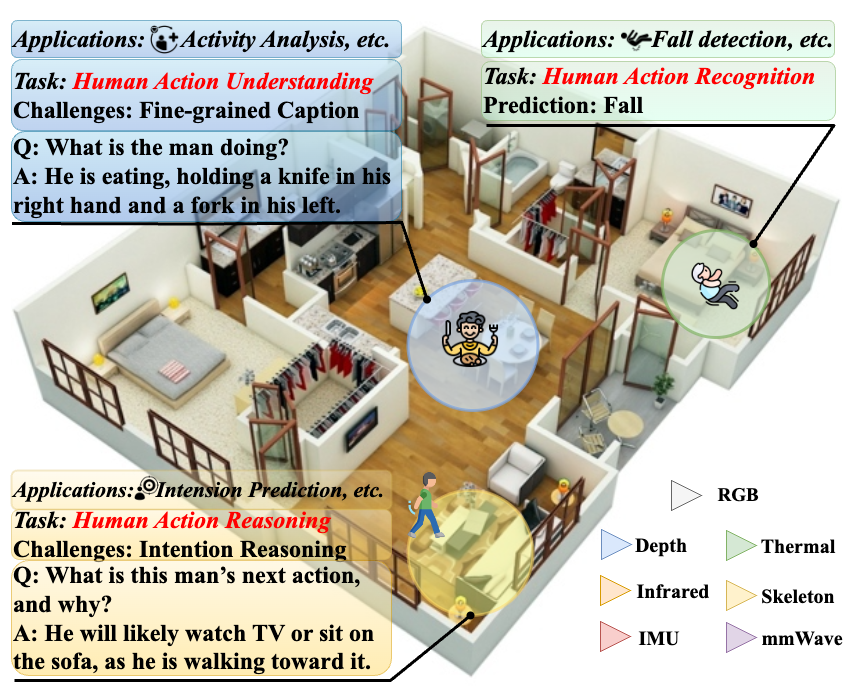
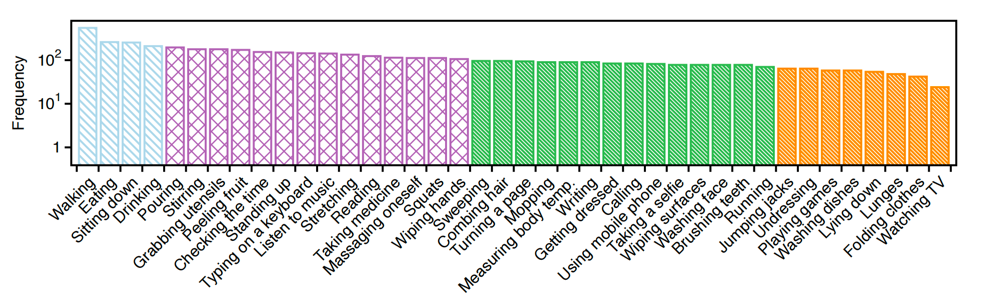
We spans a multi-room home and supports three tasks: HAR, HAU (captioning task), and HARn (question answering task), integrating diverse modalities, including RGB, depth, thermal, infrared, IMU, skeleton, and mmWave, to enable robust perception and reasoning in complex indoor contexts.
CUHK-X was collected using a sophisticated multi-sensor setup ensuring synchronized data capture across all modalities:
RGB-D camera providing color and depth information
mmWave sensing for privacy-preserving motion detection
Motion and orientation tracking with high temporal resolution
Heat signature analysis for environmental robustness
Temporal alignment across all modalities for consistent analysis

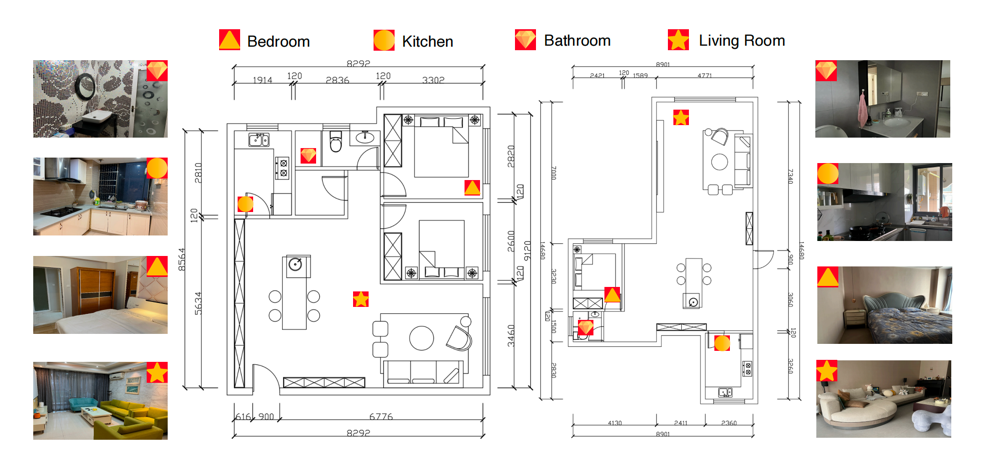
Layout with room-wise visual annotations (Bedroom, Kitchen, Bathroom, and Living Room) showing corresponding example images and sensor placements. The icon indicates the location of the ambient sensor:
CUHK-X provides three comprehensive benchmarks that progressively increase in complexity, from basic recognition to advanced reasoning:
Objective: Traditional action classification across modalities
Objective: Comprehend actions through contextual integration
Objective: Infer intentions and causal relationships
Leveraging Large Language Models to generate consistent, logical activity descriptions that participants then perform. This approach ensures:
Activities follow natural progression and causality
Actions are contextually appropriate
Quality assurance for generated scenarios
Efficient generation of diverse scenarios
CUHK-X represents a significant advancement in multimodal human activity datasets, featuring:
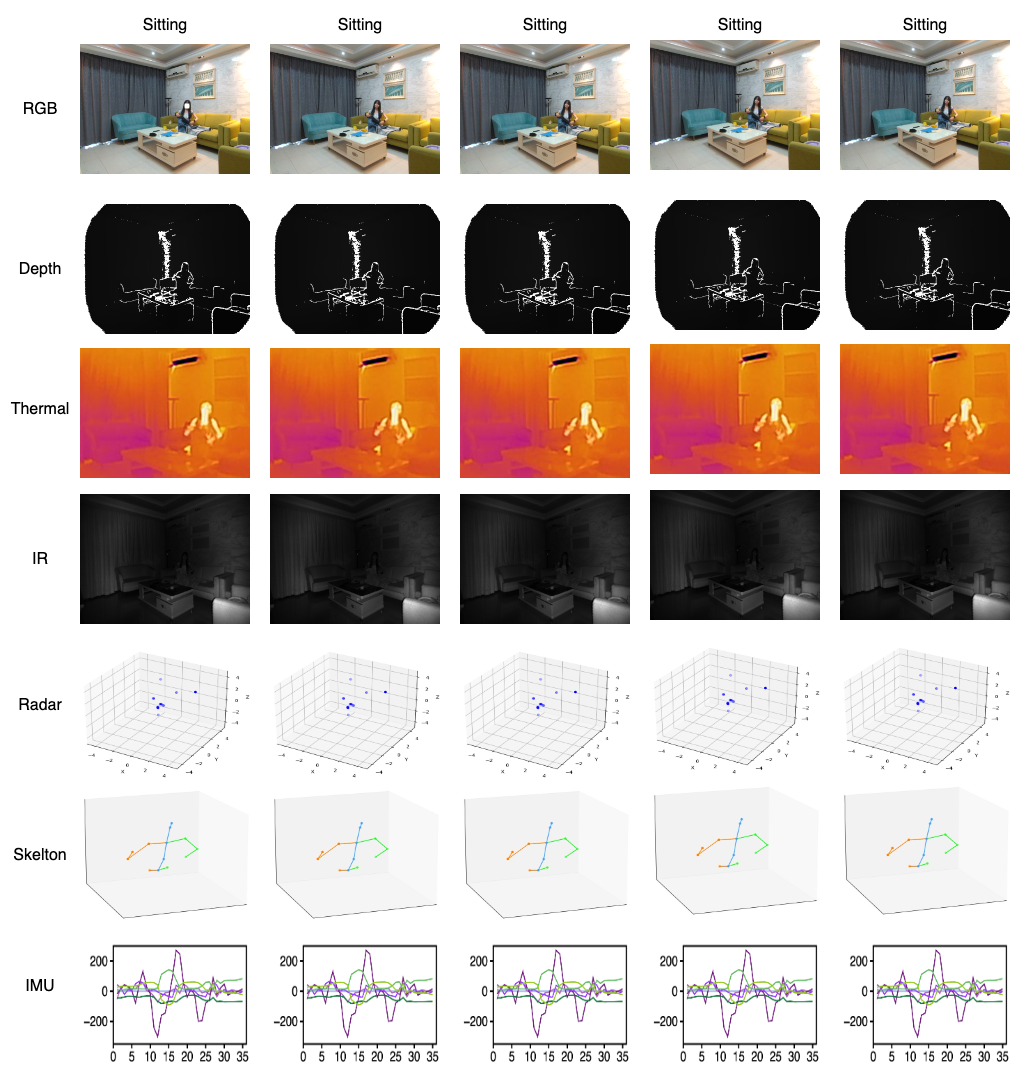
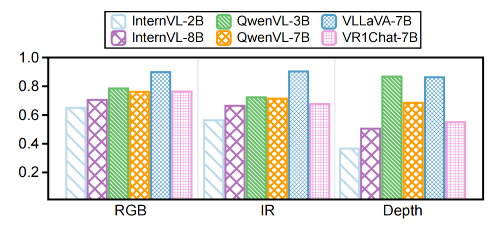
This is an example that includes seven modalities: RGB, IR, Thermal, Depth, Skeleton, Radar, and IMU, which were recorded at the same time. We have a 9-axis IMU, but we've only shown these data for simplicity.
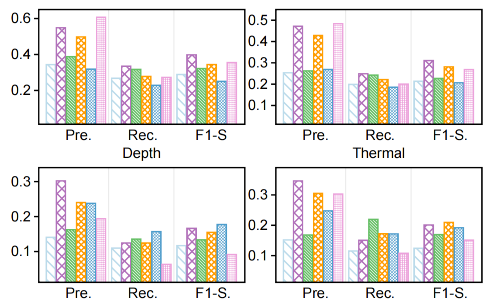
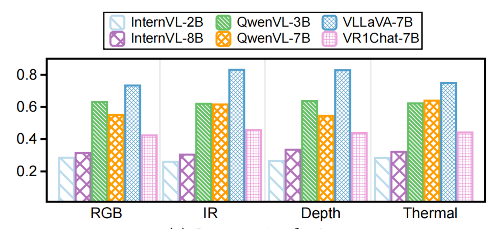
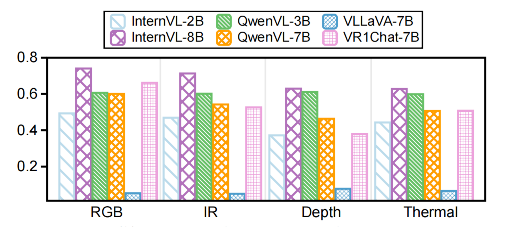
Our comprehensive evaluation across the three benchmarks reveals several important insights:
| Modality | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| RGB | 90.89% | 92.24% | 91.02% | 91.28% |
| Depth | 90.46% | 91.76% | 90.75% | 90.93% |
| IR | 90.22% | 91.53% | 89.94% | 90.46% |
| Thermal | 92.57% | 93.54% | 93.50% | 93.36% |
| mmWave | 46.63% | 48.29% | 46.63% | 44.53% |
| IMU | 45.52% | 40.84% | 38.00% | 38.32% |
| Skeleton | 79.08% | 91.46% | 79.08% | 84.17% |
If you use CUHK-X in your research, please cite our paper:
@article{jiang2025large,
title={A Large-Scale Multimodal Dataset and Benchmarks for Human Activity Scene Understanding and Reasoning},
author={Jiang, Siyang and Yuan, Mu and Ji, Xiang and Yang, Bufang and Liu, Zeyu and Xu, Lilin and Li, Yang and He, Yuting and Dong, Liran and Lu, Wenrui and others},
journal={arXiv preprint arXiv:2512.07136},
year={2025}
}
For dataset access, questions, or collaborations:
We thank all participants who contributed to the CUHK-X dataset collection. Special acknowledgments to the CUHK research team and collaborators who made this comprehensive multimodal dataset possible. The hardware setup and synchronization infrastructure were crucial for achieving the quality and scale of CUHK-X. The CUHK-X dataset creators obtained approval from an Institutional Review Board (IRB) to conduct their study and collect data from human subjects.
All datasets used in this study were accessed and used under explicit authorization from their respective owners.
CUHK-X aims to advance research in healthcare monitoring, smart environments, and privacy-preserving human activity understanding. We hope this dataset serves as a valuable resource for the research community to develop more robust and practical human activity recognition systems.